Flink Series, Part 0: Overview
What is Apache Flink, what problem does it solve, and how does it differ from Spark Streaming? A roadmap for the series.
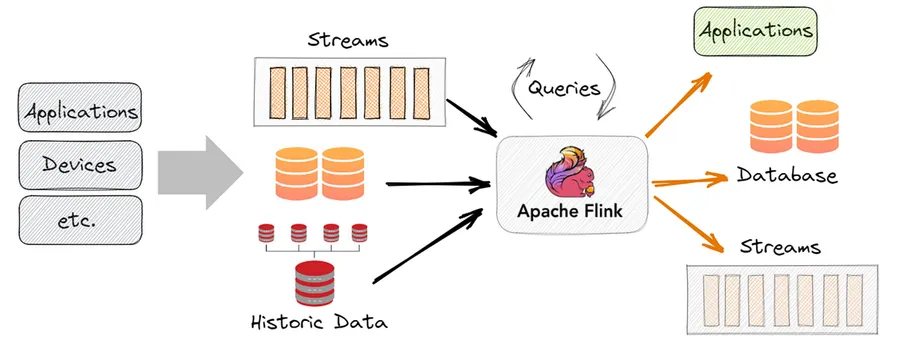
What Is Apache Flink?
Apache Flink is an open-source, distributed stream processing framework. It was born at TU Berlin in 2010 as the Stratosphere research project and entered the Apache incubator in 2014. Today it is one of the two dominant engines for large-scale stream processing — the other being Spark Structured Streaming.
The core design philosophy is stream-first: in Flink, batch processing is a special case of streaming (a bounded stream), not the other way around. This is the opposite of Spark, which grew up as a batch engine and added streaming later.
The Problem Flink Solves
Traditional batch pipelines process yesterday’s data today. That is fine for daily reports, but inadequate for:
- Fraud detection (you need to act within milliseconds, not hours)
- Real-time dashboards (users expect live numbers)
- Event-driven microservices (systems react to things as they happen)
- IoT telemetry (sensors emit continuous data that never stops)
Flink is designed to process an unbounded stream of events with low latency, correct results, and fault tolerance. You can think of it as a database that processes rows as they arrive rather than after they are stored.
Flink vs Spark Streaming
Both Flink and Spark can process streaming data, but they make different trade-offs:
| Flink | Spark Structured Streaming | |
|---|---|---|
| Model | True streaming (event-by-event) | Micro-batch (process every N seconds) |
| Latency | Milliseconds | Seconds |
| Event-time support | Native, first-class | Available but more complex |
| State management | Built-in, highly optimized | Limited compared to Flink |
| Batch support | Yes (bounded streams) | Yes (primary use case) |
Choose Flink when: latency matters (sub-second), event-time correctness is critical, or you have complex stateful operations.
Choose Spark when: you have a mixed batch+streaming workload, your team already knows Spark, or you need tight integration with Spark SQL and Delta Lake.
Flink Architecture
A Flink deployment has two main components:
JobManager — the master. It:
- Accepts job submissions
- Builds the execution graph from your code
- Schedules tasks to TaskManagers
- Coordinates checkpoints (more on this in Part 4)
TaskManager — the workers. Each TaskManager has a fixed number of slots. A slot is the unit of parallelism — one task runs in one slot. If your job has parallelism 8, you need at least 8 slots across your TaskManagers.
Client → JobManager → TaskManager (slots: [task][task][task])
→ TaskManager (slots: [task][task][task])
→ TaskManager (slots: [task][task])Data flows between tasks as a pipeline: output from one operator is fed directly to the next without going through external storage.
When to Choose Flink
Flink is the right tool when:
- You need true low latency — micro-batching in Spark has irreducible overhead from scheduling. Flink processes events as they arrive.
- Event-time correctness matters — Flink’s watermark system handles out-of-order events elegantly. If your events can arrive late (mobile apps, edge devices), Flink handles this natively.
- You have complex stateful operations — running aggregates, sessionization, pattern detection. Flink’s state backends (RocksDB) can store terabytes of state on disk efficiently.
- You need exactly-once guarantees end-to-end — Flink’s checkpointing + two-phase commit protocol makes this reliable.
The Series Roadmap
This series covers Flink from first principles to production:
- Part 0 (this post) — Overview, philosophy, and architecture
- Part 1 — DataStream API: reading, transforming, and writing streams
- Part 2 — Time & Windows: event time, watermarks, tumbling/sliding/session windows
- Part 3 — State Management: keyed state, state backends, TTL
- Part 4 — Exactly-Once & Checkpointing: how Flink guarantees correctness
- Part 5 — Performance & Production: backpressure, tuning, monitoring
Prerequisites
This series assumes:
- Comfort with Python or Java (examples will use PyFlink and Java where appropriate)
- Basic understanding of Kafka (used as source/sink in examples)
- Familiarity with distributed systems concepts (partitioning, fault tolerance)
You do not need prior Flink experience. That is what this series is for.
Next: The DataStream API