Writing about data platform, distributed systems, and machine learning.
The complete lifecycle of a write — from index request to durable disk storage. Translog as Elasticsearch's WAL, refresh vs flush, and tuning durability vs throughput.
What changes when threads become cheap? Understand carrier threads, continuations, pinning, StructuredTaskScope, and how virtual threads flip the economics of I/O-bound Java services.
Node roles, primary vs replica shards, the write path from primary to replicas, split-brain prevention with quorum, and observing cluster recovery under node failure.
Why can't you just wrap a HashMap in synchronized? Explore ConcurrentHashMap's node-level locking, CopyOnWriteArrayList's snapshot semantics, BlockingQueue variants, and a contention benchmark.
How MySQL handles concurrent connections — thread pool, connection limits, resource management, and why connection pooling is essential.
PostgreSQL's forking process model, backend lifecycle, connection pooling with PgBouncer, background workers, and resource limits per connection.
How aggregations work internally using doc_values, bucket vs metric vs pipeline aggs, cardinality approximation with HyperLogLog++, and building analytics dashboards.
Why does tuning your thread pool size matter? Understand ThreadPoolExecutor internals, queue types, rejection policies, ForkJoinPool work-stealing, and CompletableFuture async pipelines.
How MySQL survives crashes and enables replication — binary log format, GTID, crash recovery, and streaming replication.
How PostgreSQL guarantees durability with WAL, recovers from crashes, and replicates to standbys using streaming replication and logical slots.
Query vs filter context, bool query anatomy, leaf queries, pagination strategies, and building a real product search from scratch.
How can you update shared state without any lock? Understand the CAS CPU instruction, AtomicInteger, the ABA problem, LongAdder's striping trick, and VarHandle memory access modes.
How InnoDB caches pages in memory — buffer pool, LRU eviction, dirty pages, checkpoints, and sizing.
How PostgreSQL manages memory — shared buffers, eviction policies, dirty pages, checkpoints, WAL buffers, and optimal sizing.
How a search query flows from client to shards and back, how BM25 calculates relevance scores, and how to debug scoring with the _explain API.
Why does ReentrantLock exist if synchronized works? Explore tryLock, StampedLock optimistic reads, Condition variables, and LockSupport — the primitives that underpin all of java.util.concurrent.
How MySQL optimizes queries — cost model, statistics, execution plans, and steering the optimizer with hints.
How the planner estimates costs, uses statistics, chooses join strategies, and why it sometimes picks seq scans over indexes.
How Elasticsearch stores fields in multiple representations — _source, inverted index, doc_values, fielddata — and why the wrong mapping kills performance.
What does synchronized actually do at the JVM level? Explore object headers, lock state inflation from biased to fat locks, wait/notify semantics, and deadlock diagnosis with jstack.
How MySQL indexes work — B-tree structure, clustered vs secondary, covering indexes, adaptive hash indexes, and index fragmentation.
How PostgreSQL indexes work — B-tree structure, scans, deduplication, index types, bloat detection, and when the planner uses them.
How Elasticsearch splits indexes into shards, how each shard is a Lucene index made of immutable segments, and why refresh interval controls search freshness.
Why can a thread see stale data written by another? Understand CPU caches, write buffers, instruction reordering, and the happens-before relation that makes volatile work.
How MySQL isolates transactions — MVCC, undo logs, transaction IDs, isolation levels, and the purge thread.
How PostgreSQL handles concurrent transactions — xmin/xmax visibility rules, snapshots, isolation levels, and the vacuum process.
Operating Debezium in production: offset management, failure recovery, monitoring connector lag, replication slot health, rebalancing, and the operational patterns that keep CDC pipelines healthy.
Single Message Transforms (SMTs) for reshaping, filtering, and routing CDC events. Field extraction, topic routing, sensitive data masking, and when to reach for a stream processor.
Running Pekko in production: Kafka connectors, OpenTelemetry distributed tracing, health checks, dispatcher tuning, Kubernetes deployment, and migrating from Akka.
How Debezium captures existing data before streaming live changes. All snapshot modes explained — initial, never, always, when_needed — plus isolation guarantees and large-table strategies.
How Elasticsearch stores text for full-text search — inverted index structure, analyzers, tokenizers, token filters, and practical inspection with _analyze and _termvectors.
What really happens when you call new Thread().start()? Trace the path from Java to the OS kernel, understand thread lifecycle states, and use jstack to observe live threads.
How InnoDB stores data on disk — page structure, row format, clustered indexes, B-trees, and why the primary key matters.
Separating write models from read models with CQRS. Pekko Projection — consuming the event journal to build materialized views, exactly-once processing, and offset tracking.
How PostgreSQL stores data on disk — page structure, tuple anatomy, alignment, TOAST, and practical inspection with pageinspect.
What happens when someone alters a table. DDL propagation, Schema Registry integration, breaking vs non-breaking changes, and strategies to evolve without downtime.
Running Pekko across multiple JVMs. Cluster membership, the gossip protocol, cluster sharding for stateful actors, and singleton actors — all with practical configuration examples.
Master Claude Code with effective prompting, context management, and workflow patterns.
Landing CDC events into open table formats. Upsert and delete semantics with Delta Lake MERGE, Iceberg MERGE INTO, partition strategies, and JDBC sink for relational targets.
Protocol Buffers, generated Pekko service stubs, server and client setup, and bidirectional streaming. When to use gRPC instead of REST and how to run both side by side.
Create reusable, shareable automation with Claude Skills.
Deep dive into PostgreSQL (pgoutput) and MySQL (binlog) source connectors. Configuration reference, behavioral differences, and connector-specific gotchas.
Build REST APIs with pekko-http's routing DSL. HTTP server setup, route composition, request and response marshalling, and integrating HTTP endpoints with an actor system.
Connect Claude Code to external services and expand its capabilities with MCP.
Dissecting every field in a Debezium change event — before, after, op, source metadata, tombstones, and how the Kafka message key is structured.
Source, Flow, and Sink — the building blocks of Pekko Streams. Backpressure by design, composable pipelines, and how to process data without dropping messages or crashing.
Extend Claude Code with CLAUDE.md, slash commands, hooks, and automation.
Hands-on Docker Compose setup with PostgreSQL, Kafka, Kafka Connect, and the Debezium connector. See your first change event in under 10 minutes.
How EventSourcedBehavior works in Pekko: journals, snapshots, and recovery. Build actors whose state survives restarts by recording every change as an immutable event.
Use hooks to automate code formatting, block edits to protected files, get notified when Claude needs input, and enforce project rules.
Log-based vs query-based CDC, how PostgreSQL WAL and MySQL binlog work, what Debezium reads, and at-least-once delivery guarantees explained.
How actors start, fail, and recover. Parent-child supervision hierarchies, restart vs stop vs escalate strategies, and building self-healing systems in Pekko.
Installation, API setup, and your first Claude Code commands.
A practical guide to Change Data Capture with Debezium — from WAL internals to Delta Lake and Iceberg sinks. What you'll learn and why CDC matters.
A roadmap through Elasticsearch 8.x internals — from inverted indexes to cluster replication. Why learning the engine makes you a better search engineer.
A roadmap through Java concurrency — from threads and the memory model to virtual threads. Why getting concurrency right is hard, and what you'll learn.
A roadmap through MySQL 8.4 LTS internals — from storage engines to replication. Why understanding the engine matters and what you'll learn.
A practical guide to building concurrent, distributed, and resilient systems with Apache Pekko — the open-source fork of Akka. What you'll learn and why Pekko matters.
A roadmap through PostgreSQL 18 internals — from storage to replication. Why learning the engine matters and what you'll build.
What an actor is, how message passing replaces shared state, and how to create your first ActorSystem in Scala with Pekko Typed.
An introduction to Claude Code and how it differs from GitHub Copilot and Cursor.
What is Kubernetes, what problem it solves over bare metal and Docker, and a roadmap for running data workloads on K8s.
Pods, Deployments, Services, ConfigMaps, and Namespaces — the essential vocabulary every K8s user must know.
PersistentVolumes, PersistentVolumeClaims, StorageClasses, Secrets, and ConfigMaps — how stateful data workloads survive pod restarts.
StatefulSets, Jobs, CronJobs, and DaemonSets — the right workload type for each data engineering use case.
Deploying Flink with the Flink Kubernetes Operator and Kafka with Strimzi — the streaming stack on K8s.
Resource quotas, autoscaling (HPA/KEDA), monitoring with Prometheus and Grafana, and cluster cost management for data platforms.
Submitting Spark jobs natively to K8s, the Spark Operator, executor resource sizing, and shuffle storage.
Batch and real-time model inference, Databricks Model Serving endpoints, and orchestrating the full ML pipeline with Databricks Workflows.
Querying Iceberg from Trino, Flink, and DuckDB; expiring snapshots; rewriting data files; and keeping Iceberg tables healthy in production.
Tracking experiments, logging models and artifacts, comparing runs, and managing the model lifecycle with MLflow on Databricks.
How MERGE, UPDATE, and DELETE work in Iceberg — copy-on-write vs merge-on-read, when to use each, and the performance trade-offs.
Databricks Feature Store, FeatureEngineeringClient, FeatureLookup, training sets, and eliminating training-serving skew.
Partition transforms that derive partition values automatically, partition evolution that changes strategy without rewriting data, and why these are Iceberg's biggest ergonomic wins.
cloudFiles format, schema inference, schema evolution, and building robust incremental ingestion pipelines on Databricks.
How Hive, Glue, REST, and Nessie catalogs coordinate multi-engine access to Iceberg tables — and why the catalog abstraction is Iceberg's biggest differentiator.
Unity Catalog for governance and discovery, the medallion Bronze/Silver/Gold pattern, and Delta tables as the storage foundation.
The four-layer metadata hierarchy — table metadata, manifest lists, manifest files, and data files — and how it enables efficient scans and snapshot isolation.
Navigating the Databricks workspace, launching clusters, writing notebooks, and submitting your first PySpark job.
Creating Iceberg tables with Spark, reads, writes, MERGE, time travel, and inspecting table history.
The lakehouse platform concept, what Databricks adds on top of Spark and Delta Lake, and how it compares to alternatives.
What is Apache Iceberg, how does it differ from Delta Lake and Hudi, and why multi-engine interoperability is its defining advantage.
Writing to Delta with Structured Streaming, exactly-once guarantees, reading Delta as a stream, and Change Data Feed for downstream propagation.
Making Delta Lake queries fast — OPTIMIZE, Z-ordering, data skipping with column statistics, compaction, and partitioning strategies.
Querying historical snapshots by version or timestamp, rolling back bad writes, auditing the table history, and managing retention with VACUUM.
How Delta Lake validates schemas on write, rejects incompatible data, and handles controlled schema changes over time.
How the Delta Lake transaction log enables atomicity, serializable isolation, optimistic concurrency, and conflict resolution.
Creating Delta tables, reading and writing with Spark, Delta SQL, and what the _delta_log looks like in practice.
The data lake reliability problem, what Delta Lake adds on top of Parquet, and how it compares to Apache Iceberg and Apache Hudi.
Pre-aggregation with materialized views, replication with ReplicatedMergeTree, sharding with Distributed tables, and production monitoring.
Making ClickHouse queries faster — profiling with system.query_log, projections, query patterns, and what actually moves the needle.
How ClickHouse actually stores data — parts, granules, the sparse primary index, data-skipping indexes, and the background merge process.
Getting data into ClickHouse efficiently — batch inserts, async inserts, the Kafka table engine, S3 integration, and ingestion best practices.
Choosing the right data types, ORDER BY key, partitioning strategy, and TTL — the decisions that determine query performance before a single query runs.
The storage engine family at the heart of ClickHouse — MergeTree and its specialized variants for deduplication, aggregation, and updates.
What is ClickHouse, how does columnar storage work, and when should you use it? A roadmap for the series.
Stream processing natively inside Kafka — KStream vs KTable, stateful aggregations, joins, windowing, and state stores.
Moving data in and out of Kafka without writing custom code — connectors, transforms, and running Connect in production.
Replication, in-sync replicas, durability guarantees, and operational concerns for running Kafka in production.
Reading from Kafka at scale — consumer groups, partition assignment, offset commits, and handling rebalances.
Writing to Kafka reliably — the producer API, batching, compression, delivery guarantees, and idempotent producers.
The core data model behind Kafka — how topics are structured, why partitions matter, and how offsets track consumer position.
What is Apache Kafka, what problem does it solve, and when should you use it? A roadmap for the series.
Checkpointing, fault tolerance, exactly-once semantics, monitoring, and production performance tuning.
Per-key state tracking across events, timeouts, and RocksDB state stores for complex streaming logic.
Event time vs processing time, watermarks to handle late data, and window types for time-based aggregations.
Reading from Kafka and files, writing to Delta Lake and databases — the connectors that power real-time pipelines.
Making Flink production-ready — diagnosing backpressure, tuning parallelism, sizing network buffers, and monitoring with metrics.
The unbounded table model — how Spark Streaming treats streams as infinite DataFrames, with output modes, triggers, and writing.
How Flink guarantees end-to-end correctness after failures — Chandy-Lamport barriers, two-phase commit, checkpoints vs savepoints.
Stream processing with Apache Spark — from basics to Structured Streaming, the modern architecture for real-time data pipelines.
How Flink stores and manages state — keyed vs operator state, state backends, TTL, and practical stateful patterns.
Flink's most powerful feature — temporal reasoning over streams. Event time, watermarks, and window types explained.
The fundamental building block of Flink — how to read, transform, and write streams using the DataStream API.
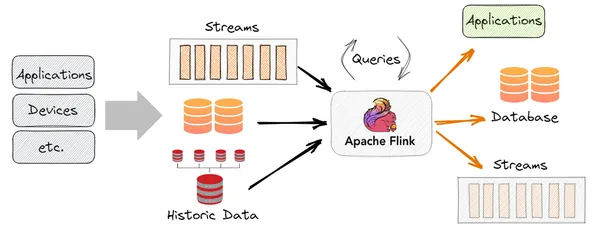
What is Apache Flink, what problem does it solve, and how does it differ from Spark Streaming? A roadmap for the series.
Making Spark jobs fast — partitioning, shuffles, skew, caching, and the most common bottlenecks in production.
Real-time data processing with Spark Structured Streaming — micro-batches, triggers, watermarks, and output modes.
The practical Spark API — working with structured data using DataFrames, schemas, and SQL queries.
Understanding Resilient Distributed Datasets — the foundation of Spark's execution model, transformations, actions, and lazy evaluation.
A high-level introduction to Apache Spark — what it is, why it exists, and where it fits in the modern data stack.
A deep dive into Flink's checkpointing mechanism and how it guarantees exactly-once processing even when jobs fail and restart.
Lessons from building internal data platforms: what makes them last, what kills them, and the principles I try to apply.